
The OpenAI models released last week are a game changer for large language models (LLMs), which have for the last year-and-a-half been rather stable in performance. Some had caught up with OpenAI’s ChatGPT-4, but nobody had significantly surpassed it. The frontier had not advanced far.
This had raised speculation, including my own, over whether the scaling of ever larger training datasets, ever larger numbers of parameters in the models, and ever longer training runs had reached some kind of limit. That limit might be related to operational issues surrounding compute cost and capacity that would be relaxed over time. Or maybe there was a more substantive limit of the underlying paradigm of the transformer model architecture. The conclusion was that something else, a novel innovation, could be needed for further gains.
One such innovation appears now to have emerged.
The GPT-4 o1 model is a change of paradigm in the sense that it is not simply the same thing scaled bigger, but rather that lit thinks (or computes) more at inference time (i.e. at the time of use). It is shifting the distribution of computation from being almost entirely at training time, when the model is developed, towards increased computation at inference time, when the model is used.
This model is not scaling more data, parameters, or training compute to increase its knowledge, but it is scaling more compute and data to train specifically for problem solving and in particular it is scaling the compute at the time of use. It has in itself embedded steps to evaluate and improve its solutions to problems and shows much better performance than GPT-4 in solving problems that involve complex, multistep reasoning. It’s much more capable at generating detailed code from ambiguous descriptions and generating coherent, structured content over much longer texts, for instance.
Before diving into this, here’s a very brief glossary of key AI terms:
Training Data: The large, diverse text corpus used to teach AI models how to understand and generate language.
Parameters: Internal model values adjusted during training, capturing patterns in the data for generating language.
Inference: The process of generating outputs (like text) from a trained model based on new inputs.
Compute: The computational power required to train and run large AI models, typically involving high-performance hardware.
Tokens: Basic units of text (words, subwords, or characters) that models process when generating language.
Autoregressive Models: Models that generate text one token at a time, with each token partially depending on the preceding ones.
The Preliminaries
A key insight to get us started is in the classic 2019 article by the famous computer scientist Rich Sutton titled “The Bitter Lesson“:
“The biggest lesson that can be read from 70 years of AI research is that general methods that leverage computation are ultimately the most effective, and by a large margin…Seeking an improvement that makes a difference in the shorter term, researchers seek to leverage their human knowledge of the domain, but the only thing that matters in the long run is the leveraging of computation.
One thing that should be learned from the bitter lesson is the great power of general purpose methods, of methods that continue to scale with increased computation even as the available computation becomes very great. The two methods that seem to scale arbitrarily in this way are search and learning.”
This has the key implication that there is little secret sauce, little magic to Artificial Intelligence in general. It’s computation and lots of it. It’s difficult to come up with useful, novel algorithms, and in the end, increasing computing power will trump any model advantage. It’s also difficult to have a competitive advantage based on algorithms.
It is possible to have an advantage based on unique data or being able to throw more money (i.e. computation) at the problem than anyone else.
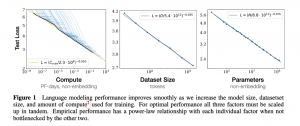
Prior research has found that for LLMs, the key dimensions of scaling are the size of the model in terms of the number of parameters, the size of the training dataset, and the amount of computation used in training the model:
The graph below from that research paper illustrates two key points. First, the relationship between scaling and these dimensions is very stable and holds over a very large range of values. More is always better, it seems. Second, to get the same marginal improvement in performance, the increase in the inputs of training data, model size, and training compute has to be ever bigger. There are declining marginal returns. This will create at least temporary slowdowns in development as the cost of adding more inputs becomes prohibitively expensive, but this is only temporary as eventually, as Sutton explains above, technological development in computation will drive down the costs again.
Imperfect Models
There are some features and limitations of these LLMs that are important to understand:
First, what they fundamentally do is predict the most likely next word (or more accurately, the next token) given the prompt and previously predicted words. There is no real “intelligence” behind it. It is simply replicating patterns of language that it has “learned” from the training data. Given the enormous amounts of data, the enormously large models, and the enormous amounts of compute, these patterns can be very complex and appear to be very “intelligent”.
Second, the models are auto-regressive in the sense that each word that it outputs influences the following words and thus the model output is path dependent. The first word that it predicted as the best output and with which it started shapes everything else that follows. This means it can get stuck on the wrong path and occasionally outputs an error when it’s unable to find a reasonable continuation.
Third, there is no truth filter or understanding embedded in the model. The output is a probabilistic sequence of words that appears to be very reasonable given the immense complexity of the patterns embedded in the model. So the models can output completely non-factual information that appears reasonable, a process generally termed “hallucination”. This is a fundamental feature of the models themselves and not something that can ever be eliminated entirely:
Fourth, prompting an LLM to “think” in steps, or generating a chain of thought (CoT), can significantly improve its ability to do more complex “reasoning.” Instead of asking simply for an answer, it is better to ask the model to think through the steps to reach the answer. Giving the model an example of a chain of thought is particularly helpful.
This turns out to be immensely powerful. In May 2024, a group of researchers from Stanford, Toyota, and Google showed that transformers can solve any problem “provided they are allowed to generate as many intermediate reasoning tokens as needed.”
In other words, if we were able to let the model run infinitely long, a transformer model could in principle solve any problem. In practice, infinity is a long time. And this is what the new o1 models improve: They search better for solutions to problems.
And therein lies the paradigm shift of the new OpenAI models, which I’ll cover in the next blog post.